
先把对话抽象成稳定事实,再和已有记忆做比对,决定新增、更新、删除或保持不变,并把结果写入向量存储、可选图存储,以及历史审计日志。
这套设计让 mem0 更接近一个面向 Agent 的长期记忆系统,参考人类的记忆模式,不是记住一大段话,而是记住一些和内容相关的facts,然后建立facts之间的关联(图数据库实现)。、】
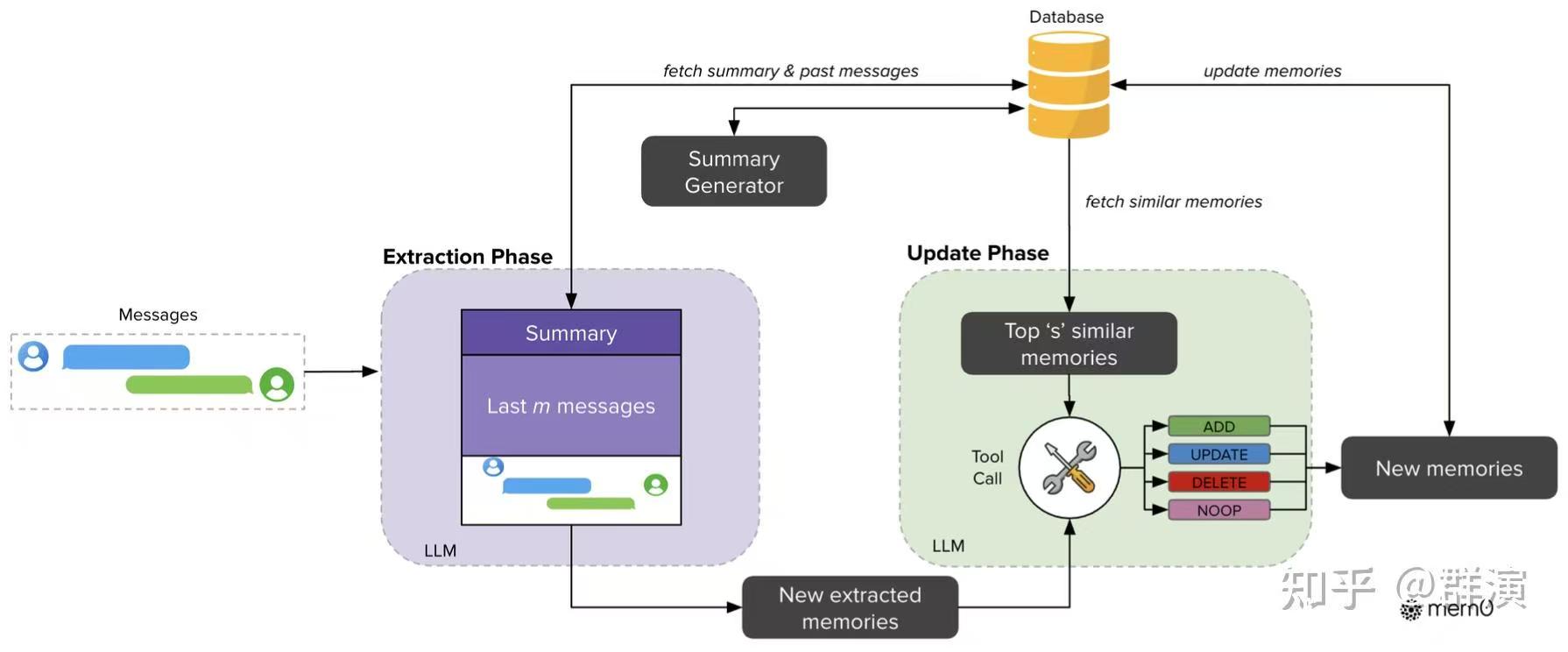
一、mem0 的主流程#
如果只看主链路,mem0 可以抽象成 5 个步骤:
- 从对话中抽取候选事实(llm的工作)
- 检索相近旧记忆,构造“新旧对比上下文”
- 让 LLM 决策
ADD / UPDATE / DELETE / NONE - 把结果写入向量存储,并可选地并行更新图谱关系
- 把所有变更写入历史数据库,形成可审计轨迹
二、核心ADD流程#
1. 作用域校验#
_build_filters_and_metadata() 要求至少提供一个作用域标识,实现能支持多用户、多 Agent、多 session 的隔离与组合检索。
2. 抽取事实#
真正的逻辑在 _add_to_vector_store()。
默认情况下,infer=True,于是 mem0 不会直接存原始消息,而是:
- 用
parse_messages()把多轮消息拼成标准文本 - 选择事实抽取提示词
- 调用 LLM 生成
facts - 解析 JSON,得到候选事实列表
3. 记忆管理#
对每条新事实,mem0 会先做 embedding,然后调用向量库搜索相似记忆(旧记忆),
拿到旧记忆后,mem0 会调用 get_update_memory_messages() 组装一段新的 prompt,交给 LLM 做决策。
然后,要求返回包含ADD,UPDATE,DELETE,NONE等指令是的结构化结果
比如用户说过“喜欢芝士披萨”,后来又说“更喜欢鸡肉披萨”,系统并不一定保留两条并列事实,而是可以把旧记忆更新掉,或者在冲突时删除旧记忆,全部由llm自主决定
然后进行入库,包含向量数据库和图数据库(可选),这里的图链路负责关系增强,主要的facts都存在了向量库中,在mem0/memory/graph_memory.py ,MemoryGraph会:
- 从文本中抽实体
- 建立实体之间的关系
- 在图数据库中查找近似节点并合并
- 对过期或矛盾关系做软删除
几个细节:
- 图关系不是简单 append,而是会做关系更新和删除判断
- 删除通常是软删除,关系会被标记为
valid = false - 节点和边都维护
mentions之类的统计信息 - 图谱检索会先做 embedding 相似召回,再对关系三元组做 BM25 重排
三、Search 流程#
- 构建作用域过滤条件
- 对 query 做 embedding
- 调用向量库搜索
- 如果开启图存储,并行执行图检索
- 如果配置了 reranker,再对向量结果二次重排
- 返回
results,并在启用图谱时附带relations
五、chatgpt总结一下#
mem0 的源码体现出一个很明确的设计取向:
把长期记忆当作一层独立基础设施来构建,而不是把检索增强里的“召回缓存”稍微包装一下。
它的关键点不在于用了多少后端,而在于这三个设计选择:
- 记忆先被抽象成事实,而不是直接保存原始对话
- 新信息进入系统前,会先和旧记忆比较,再决定增删改
- 图谱、审计日志、重排序都服务于“记忆可维护性”,而不只是“多存一些上下文”
如果从 Agent 系统设计的角度看,mem0 更像一个长期状态层。
它解决的核心问题不是“记住更多”,而是“如何把记住的内容长期保持为一个相对一致、可解释、可检索的状态空间”。